
「機械学習による電力使用量予測」
2017年06月26日
機械学習を用いて過去の電気使用量を学習し、今後の電力使用量を予測する方法を紹介します。
実行環境
| 項目 | 内容 |
|---|---|
| 機器 | MacBook Air (13-inch, Early 2015) |
| 開発言語 | Ruby with PyCall |
| 使用ライブラリ | Scikit-learn on Python |
| 開発環境 | Jupyter Notebook |
開発言語はRubyを用いますが、機械学習についてはPyCallというライブラリをもちいてPythonの機械学習ライブラリを利用します。
過去の電力使用量データのダウンロード
以下のURLにて「過去の電力使用実績」を選択し、2016年度のデータを入手します。
ダウンロードしたファイルはdataというフォルダを作成して保存します。
過去の気象データのダウンロード
以下のURLにて、上記電力使用実績と同じ期間(2016年4月1日〜2017年3月31日)の松江市における1時間おきの気象データをダウンロードします。
ダウンロードしたファイルはdataというフォルダを作成して保存します。
ライブラリの読込
PyCallを使ってデータ読込に必要なライブラリを読み込みます。
require 'pycall/import'
include PyCall::Import
pyimport 'numpy', as: 'np'
pyimport 'pandas', as: 'pd'
データ読込
電力データの読込
保存した電力データを読み込みます。
filename = "data/juyo-2016.csv"
df_kw = pd.read_csv.(filename, encoding: "SHIFT-JIS", skiprows: 2)
df_kw["KW"] = df_kw.pop.("実績(万kW)")
気象データの読込
保存した気象データを読み込みます。
filename = "data/data.csv"
df_temp = pd.read_csv.(filename, encoding: "SHIFT-JIS", skiprows: 4)
df_temp["DATETIME"] = df_temp.pop.("Unnamed: 0")
df_temp["TEMP"] = df_temp.pop.("Unnamed: 1")
データ加工
以下のスクリプトにより、電力使用実績の日時データを加工します。
require 'time'
year = []
month = []
day = []
wday = []
hour = []
ymd = []
(0..PyCall.len(df_kw)-1).each do |i|
dt = DateTime.parse(df_kw.DATE.iloc[i] + " " + df_kw.TIME.iloc[i])
year << dt.year
month << dt.month
day << dt.day
wday << dt.wday
hour << dt.hour
ymd << sprintf("%d%02d%02d%02d",dt.year, dt.month, dt.day, dt.hour).to_i
end
df_kw["YEAR"] = year
df_kw["MONTH"] = month
df_kw["DAY"] = day
df_kw["WEEK"] = wday
df_kw["HOUR"] = hour
df_kw["YMD"] = ymd
加工したデータを確認します。
df_kw.head.()2016年4月1日 0:00からのデータがあることがわかります。
DATE TIME KW YEAR MONTH DAY WEEK HOUR YMD
0 2016/4/1 0:00 581 2016 4 1 5 0 2016040100
1 2016/4/1 1:00 600 2016 4 1 5 1 2016040101
2 2016/4/1 2:00 640 2016 4 1 5 2 2016040102
3 2016/4/1 3:00 665 2016 4 1 5 3 2016040103
4 2016/4/1 4:00 658 2016 4 1 5 4 2016040104
気象データを確認します。
df_temp.head.()2016年4月1日 1:00からのデータがあることがわかります。
品質情報 均質番号 ETIME TEMP
0 8 1 2016/4/1 1:00:00 12.8
1 8 1 2016/4/1 2:00:00 12.5
2 8 1 2016/4/1 3:00:00 12.3
3 8 1 2016/4/1 4:00:00 12.2
4 8 1 2016/4/1 5:00:00 12.2
電力データと気象データが1時間ずれているので、電力データを1時間削ります。
df_kw = df_kw[df_kw.index > 0]
df_kw = df_kw.reset_index.()
電力データを加工した結果、気象データが1時間多くなるので、電力データにデータ数を合わせます。
row, col = df_kw.shape
df_temp = df_temp[df_temp.index < row]
両方のデータ数をあわせた後、電力データに気温データを追加します。
df_kw["TEMP"] = df_temp["TEMP"]
学習データの作成
入力データと出力データ
学習データの作成として、予測したい電力使用量のデータを出力、それ以外のデータを入力としてデータを分割します。
x_cols = ["MONTH","WEEK","HOUR","TEMP"]
y_cols = ["KW"]
x = df_kw[x_cols].as_matrix.().astype.("float")
y = df_kw[y_cols].as_matrix.().astype.("int").flatten.()
学習データと検証データ
学習データからランダムにデータを抜粋し、検証データを作成します。
pyfrom 'sklearn.cross_validation', import: :train_test_split
x_train, x_test, y_train, y_test = train_test_split.(x, y, test_size: 0.1, random_state: 42)
データの正規化
入力データを正規化し、標準偏差を1にそろえます。
pyfrom 'sklearn.preprocessing', import: :StandardScaler
scaler = StandardScaler.()
scaler.fit.(x_train)
x_train = scaler.transform.(x_train)
x_test = scaler.transform.(x_test)学習
ランダムフォレストという手法を使ってデータを学習します。
pyfrom 'sklearn.ensemble', import: :RandomForestRegressor
model = RandomForestRegressor.(random_state: 42)
model.fit.(x_train, y_train)
スコアを計算します。
model.score.(x_test,y_test)
0.8814301538086063実行結果から約88%の精度であることがわかります。
検証
予測値を取得し、実績値と比較します。
result = model.predict.(x_test)
df_result = pd.DataFrame.()
df_result["result"] = result
df_result["y_test"] = y_test
df_result.head.()数値を表示すると以下のとおり。
result y_test
0 778.8 817
1 702.0 739
2 754.2 801
3 759.5 733
4 744.2 804数値ではわかりにくいので、グラフを描画します。
pyimport 'matplotlib.pyplot', as: 'plt'
require 'matplotlib/iruby'
Matplotlib::IRuby.activate
plt.figure.(figsize: PyCall.tuple(10, 3))
plt.plot.(df_result.head.(100))
plt.show.()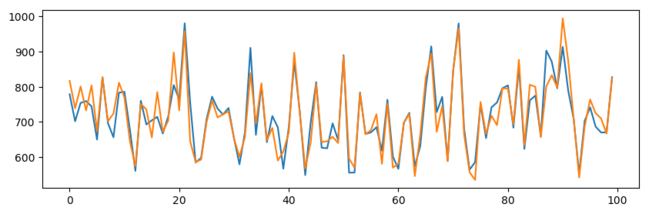
以上が電力使用量予測を機械学習で行う実例でした。
もし、同じようなデータをお持ちの方がおられましたら是非そのデータを使って機械学習を試してみてください。
(専門研究員 木村 忍)
