
共同研究「類似文章の検索における機械学習の適用可能性検証」レポート
2020年06月30日
しまねソフト研究開発センターでは、株式会社テクノプロジェクトと「類似文章の検索における機械学習の適用可能性検証」をテーマとして共同研究を行いました。
以下に取組の内容を紹介します。
共同研究の背景
論文にまつわる文書処理について
大学などの研究機関では、学術誌・学会誌等に掲載する論文の出版に至るまでの過程において、対象となる”研究領域の専門知識をもった人”による「執筆」、「翻訳」、「査読」などの文章処理を伴う作業が多く存在する。そのため、研究者は本質的な研究以外の活動に多くの時間を割かざるをえない現状があり、研究活動の加速や活発化を図る上での課題となっている。
執筆された論文が出版に至るまでの過程で生じる文書処理は、文章中に研究領域特有の「専門用語」が多く登場するほか、論文特有の「書式」を処理する必要があるため、ルールやパターンをプログラミングしてシステム化を図ることが難しい。そのため、機械学習等のAI技術を活用することで、高度な文章処理を実現することが期待される領域といえる。
文書処理におけるAI技術について
近年の文書処理を扱うAI技術の大きな進展にBERTの考案がある。BERTは2018年10月にGoogleが発表したモデルで、発表当時、先行モデルを凌駕する性能を達成したことで話題となった。
現在、BERTはGoogle検索をはじめとして、翻訳、文書分類等の様々な文書処理を扱うサービスに応用されているが、 その一方で、応用する上での難点も存在する。BERTは3億4500万ものパラメータを持つモデルもあり、学習には高性能なGPU、あるいは、TPUといった非常に大きな計算リソースが必要となる。
共同研究の概要
類似文章の検索機能の検証
論文にまつわる文書処理においては、先行研究調査、査読における引用文献調査など類似する文章を検索可能とすることで効率化が可能な場面がある。本研究では、BERT、および、RoBERTaと呼ばれるBERTの発展手法を利用して、類似文章検索機能の実現可能性を検証した。
クラウドを用いた高性能リソースの利用可能性検証
前述の通り、BERTおよびその発展手法は学習に非常に大きな計算リソースが必要となる。しかし、検証のためだけに高価なGPUマシンを調達するのはコストパフォーマンスが悪い。そこで、クラウドサービスで提供されている仮想環境を利用して検証環境を構築し、モデルの学習にかかる多大な計算量が処理可能であるか検証した。
共同研究実施期間
令和元年12月2日 ~ 令和2年3月31日
実施内容
特徴量の解析
BERT、および、BERTの発展手法は文書処理タスクの結果(感情分析における快/不快や翻訳における翻訳語文書など)、とは別に入力した文の特徴量を出力することが可能である。この特徴量を解析し、特徴量の比較による類似文書の検索が可能であるか否かを検証した。
ファインチューニング
BERTはプレトレーニングとファインチューニングという二つの工程で自然言語を学習する。プレトレーニングでは単語の意味や文法法則などの自然言語の基礎となる情報を、ファインチューニングでは感情分析や翻訳等の目的に応じたタスクを学習させる。本研究では、クラウド環境を利用することで巨大なモデルの教育が可能か否かを明らかにするためにクラウド環境上でRoBERTaのファインチューニングを行った。また、ファインチューニングに用いるデータには、文章の類似度を評価するタスクに用いられるSTS-Bと呼ばれるデータセットを利用した。
試用したリソース
RoBETRa はプレトレーニング済みのモデル、および、ファインチューニングを行うソースコードがオープンソースで公開されている。上述の「特徴量の解析」についてはプレトレーニング済みのモデルを利用した。「ファインチューニング」についてはプレトレーニング済みのモデルに対し、ファインチューニングを行うソースコードを適用することで行った。
- クラウドを用いた検証環境
本研究では、AWS(Amazon Web Services)上にGPUインスタンスを構築し検証作業を行うことで、その実用性についても評価した。以下に、利用環境の模式図と示す。
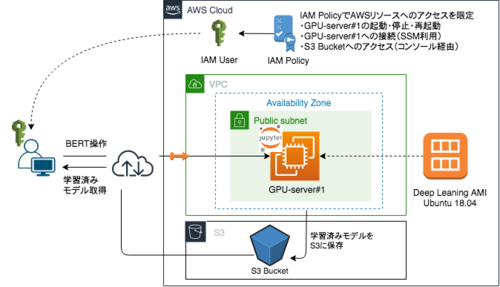
共同研究から得られたこと、分かったこと
類似文の検索機能の実現可能性についての検証結果
文の特徴量をRoBERTaで解析し、他の文の特徴量と比較するプログラムを試作した。以下に内視鏡分野のガイドライン(https://onlinelibrary.wiley.com/doi/10.1111/den.13654 全42pの英文)について文の特徴量を比較した結果の例を示す。ここで、クエリと呼ぶ文は作業者が作成した文である。検索結果として示す文は、ガイドライン全文中でクエリと最も類似する特徴量を持つ文である。

(i)のようにドキュメント中からクエリと同じ話題を検索可能なケースがあることが確認できた。また、(ii)のように類似する意味の単語であれば(Application と Indication、decide と determine など)、その違いを吸収して同じ話題を扱う文が検索可能なケースがあることが確認できた。以上の結果は、ある程度柔軟性のある検索が可能であることを示しており、RoBERTa により論文にまつわる文書処理の効率化が可能なことを示唆する結果である。
一方で、(iii)に示すように専門用語が多く使われている文については、作業者も専門用語を正しく理解できておらず、適切な検索が行えているか判断が難しい。さらに(iV)のように見当違いな検索結果を挙げるケースも散見されたため、実用化に向けて(iii)のようなケースが適切であるかを明らかにすること、および、(iV)のようなケースがどの程度の割合で発生するかを明らかにすることが必要である。
クラウド活用に関する知見
以下に今回利用したクラウドサービス(AWS)で利用可能なGPUの利用料金およびスペックの一部を示す。
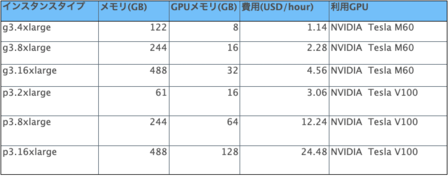
一覧に記されている通り、AWSのGPUマシンは時間単位の費用で利用可能である。上記のGPUが10,000USD前後の金額で取引されていることに加えて、本研究で行ったファインチューニング(文の解析、および、解析結果に基づいたモデルのアップデート)1回分に要した時間が1時間に満たなかったことから、今回のような検証フェーズなど用途に応じては、クラウドサービスを利用することで費用を数十分の一~数百分の一程度に抑えることができることがわかった。
また、本研究においては当初用意した仮想マシンのGPUメモリ容量やストレージ容量が足りず、ファイチューニングが進められない状況に陥ったが、クラウドサービスのコンソール(Webブラウザで動作)を用いて容易かつ短時間で対処(容量の増強)することができた。利用するデータ量やモデルの規模、学習に用いるソースコードに依存して、マシンのメモリ容量やストレージ容量は変化するような状況に対しても、クラウドサービスの柔軟性はメリットとなることがわかった。
なお、今回のGPUマシンはAWSが提供するAWS Deep Learning AMI (DLAMI) を用いて構築したが、ストレージ容量全体にAMIが利用している容量があることを考慮に入れて見積もる必要があることが分かった。本研究では当初90 GBの容量を確保し作業を開始したが、開始時点で7割(64GB)をAMIが使用しており、自由に利用できるディスク容量のは26GB程度であった。AMIを用いてインスタンスを構成する場合、このように、AMIが数十GBもの容量を占有する場合があるため、インスタンスの容量を決定するにあたってはAMIが利用する容量を把握する必要がある。
今後の事業方針等について
論文にまつわる文書処理について
論文にまつわる文書処理のうち、類似文章の検索機能の実現にあたり、RoBERTaを活用することで作業が効率化できることを示唆する結果が得られた。今回は定量的な性能の評価までは行えておらず、また、高度に専門的な文章については現状、実用性を判断できていない。実用性を判断するために、性能についての詳細な計測、および、専門家に意見を伺うことが必要である。
また、今回AWS環境でファインチューニングを行ったモデルについても今回と同様の手法で類似文書の検索が行える。ファインチューニングによる性能の向上も期待できるため、今後、必要に応じて今回利用した手法を適用したい。
クラウドサービスの活用について
クラウドサービスを活用することで、高価なGPUマシンを調達することなく目的の検証作業を行えた。また、採用したサービスを活用する際の注意点などを洗い出すことができた。今後、論文にまつわる文書処理を効率化するシステム構成を検討する、あるいは運用する際の参考になると考えている。
担当研究員からのコメント
しまねソフト研究開発センター 専門研究員 高木 丈智
深層学習(ディープラーニング)の発展と普及により、画像処理や自然言語処理など非構造化データの活用において、コンピューターシステムが実現できる領域は一層拡大すると考えられます。ディープラーニングの実用においては、適切なデータを大量に用意し高性能な計算リソースを用いてモデルを学習させることが必要とされてきましたが、大量のデータが用意できない環境に対するアプローチや、クラウドを活用した高性能なコンピュータリソースの確保といった選択肢が増えるなど、実用に向けた障壁はテクノロジーと環境の両面で下がっていくことが予想されます。本研究で得られた技術的な検証結果に加えて、クラウドサービスの活用から得られた成果が、今後の事業化に活かされることを願っています。
問い合わせ先
公益財団法人しまね産業振興財団 しまねソフト研究開発センター(ITOC) 担当:広瀬
〒690-0826 島根県松江市学園南1丁目2−1くにびきメッセ西棟4F
TEL:0852-61-2225 FAX: 0852-61-3322 itoc@s-itoc.jp
