
共同研究「建築設備工事業向け積算システム「積算らいでん」におけるAI活用可能性の検討」レポート
2021年03月24日
しまねソフト研究開発センターでは、株式会社シーエスエーと「建築設備工事業向け積算システム「積算らいでん」におけるAI活用可能性の検討」をテーマとして共同研究を行いました。
以下に取組の内容を紹介します。
共同研究の目的
「積算らいでん」の改良・改善につながるAI技術の活用可能性について検討する。特に、「積算らいでん」のオプション機能である「取込名人」が提供するマスタ引き当て機能(以下、「引き当て機能」と記す)の改良・改善につながる機械学習等の技術の適用可能性について調査・評価を行い、その活用について検討する。
共同研究の内容及び目標
取込名人の「引き当て」機能には、独自アルゴリズムを用いた適合度の計算を用いているが、以下の課題があり、取り込み機能の利便性を低下させる要因になっている。
- 精度面の課題: マスタの文字数が長くなるほど適合率が低下する
- 速度面の課題: 文字数、マスタデータ数に応じて処理速度が低下する
本共同研究では、独自アルゴリズムの改良・改善や、機械学習等を用いた新たなアルゴリズムの実装可能性について知見を得るため以下を実施した。
<1>引き当てアルゴリズムへの形態素解析等の適用可能性評価
<2>引き当て機能への機械学習(分類モデル)等の適用可能性検討
<3>サンプルコード等を用いた適用技術のレクチャー
共同研究実施期間
令和2年7月1日 ~ 令和2年12月28日
共同研究から得られたこと、分かったこと
<1>引き当てアルゴリズムへの形態素解析等の適用可能性評価
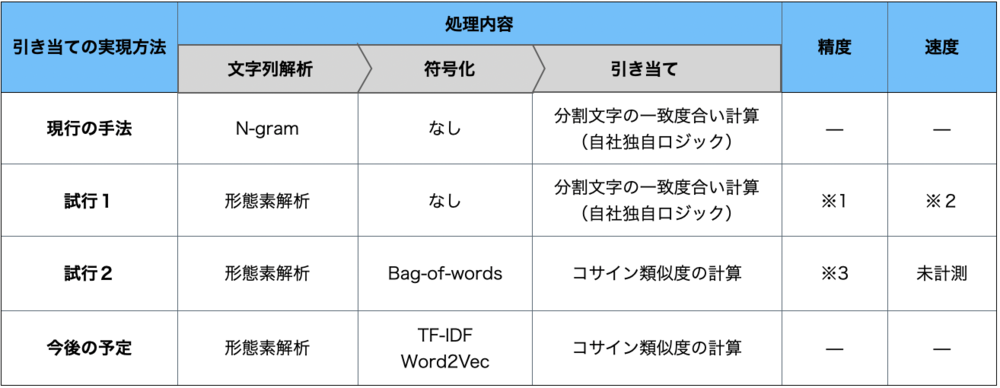
積算らいでんの引き当て処理は、N-gramを用いた文字列解析(分割)と、分割した文字列の一致度合いの評価(自社独自ロジック)の2段階で実現している。今回は、引き当てアルゴリズムの改善案を以下の通り検討し、評価用のプログラムを作成して適用可能性を評価した。
- 試行1:形態素解析を用いた引き当て改善
形態素解析を行ったデータを「現行の手法」と同様に、文字列の一致度合いを評価により引き当てるプログラムを作成・試行したところ、検索対象とする文字列に特殊な単語・記号などの表現が含まれている場合、期待通りに文字列が分割されず、結果として期待する引き当て結果が得られないケースが確認された。形態素解析用のユーザー辞書に特殊な表現を登録しておくことで改善が可能である事が分かった(下表※1)が、引き当ての精度が形態素解析用のユーザー辞書の品質に依存するため、ユーザー辞書の品質管理が課題となりうる。
処理速度については、実運用されているシステムと同程度のマスターレコード数で検証した結果、現行の手法と比較して30%程度の性能劣化が見られた(下表※2)。
- 試行2:コサイン類似度を用いた引き当て改善
形態素解析を行なったデータを「Bag-of-words」で符号化したのち、コサイン類似度を用いて引き当てするサンプルプログラムを作成・試行したところ、引き当て精度については現行の手法と比較して向上するケースが確認された(下表※3)。今回はサンプルプログラムを用いた試行に留まったため、アプリケーションへの実装方式の検討や定量的な精度の評価が必要である。また、形態素解析の処理部については、「試行1」と同様にユーザー辞書の整備が課題となりうる。
今後は、別の符号化手法(TF-IDF、Word2Vecなど)を組み合わせた場合についても精度や問題点の評価を行い、製品への組み込み方法について検討を行う予定である。
<2>引き当て機能への機械学習(分類モデル)等の適用可能性検討
引き当て機能への機械学習の適用にあたっては、引き当て対象となる積算らいでんの「マスタデータ」を分類ラベルとする多クラス分類として問題設定を行い適用可能性の評価を行おうと考えたが、データの初期分析の段階で以下の課題が分かったため、一般的な多クラス分類として扱うことが難しいことが分かった。
- 分類ラベル数に対する学習データ数が少なすぎる(学習データ数:ラベル数=31,090:27,343)
- 分類対象の文字列が「短い」ため効果的な特徴量がとらえにくい(例:「分電盤 1L-K1」)
一般的なテキストの多クラス分類として技術適用することは難しいことが分かったものの、“BERT(Google製の汎用言語モデル)”を用いた転移学習や“Erasticsearch”を用いた全文検索のアプローチの適応可能性について、今後評価・検討する予定である。
<3>サンプルコード等を用いた適用技術のレクチャー
形態素解析や機械学習等の適用方法について、しまねソフト研究開発センターからレクチャーを受けたことで、既存のアルゴリズムには無かった課題解決の切り口やヒントを得ることができた。また、新たな技術の適用にあたって技術的な要件への適合度だけでなく、辞書データや機械学習モデルのメンテナンスなど運用面での実現可能性を合わせて検討すべきであることを認識することができた。
今後の事業方針等について
今回の研究で得られた知見をもとに、具体的な実装方法の検討および対応効果について社内にて協議を行う。機能強化内容や実装方法については、実装に必要な対応工数や性能に対する影響について検証が必要となるため、他の機能強化との優先度やお客様のニーズも考慮し、各支店の営業担当とも協議の上、状況を見ながら対応優先度を決定する。
担当研究員からのコメント
しまねソフト研究開発センター 専門研究員 高木 丈智
本研究を通じて対象のアプリケーションの改良・改善は「形態素解析」や「符号化」、「コサイン類似度の計算」といった自然言語処理の技術が応用可能であることがわかりました。活動を通じて得られた技術の選択肢とシステムの機能要件・非機能要件との適合性が評価され、アプリケーションの価値向上が実現されることを期待します。
問い合わせ先
公益財団法人しまね産業振興財団 しまねソフト研究開発センター(ITOC) 担当:広瀬
〒690-0826 島根県松江市学園南1丁目2−1くにびきメッセ西棟4F
TEL:0852-61-2225 FAX: 0852-61-3322 itoc@s-itoc.jp
